Research Introduction
Our Lab is divided into two research groups, based on their research subject.
Human Sensing Group
We conduct researches to recoginize written characters, human action, human attributes, etc. from images and videos taken with digital cameras and surveillance cameras. We also research on applied technologies like wide-area monitoring systems.
Object Recognition using various sensors
Humans recognize objects from visible light, but with the recent development of sensor technology, sensors can now detect light amounts that humans cannot detect and invisible light such as infrared rays.
We aim at monitoring elderly people by efficiently using information from such sensors.



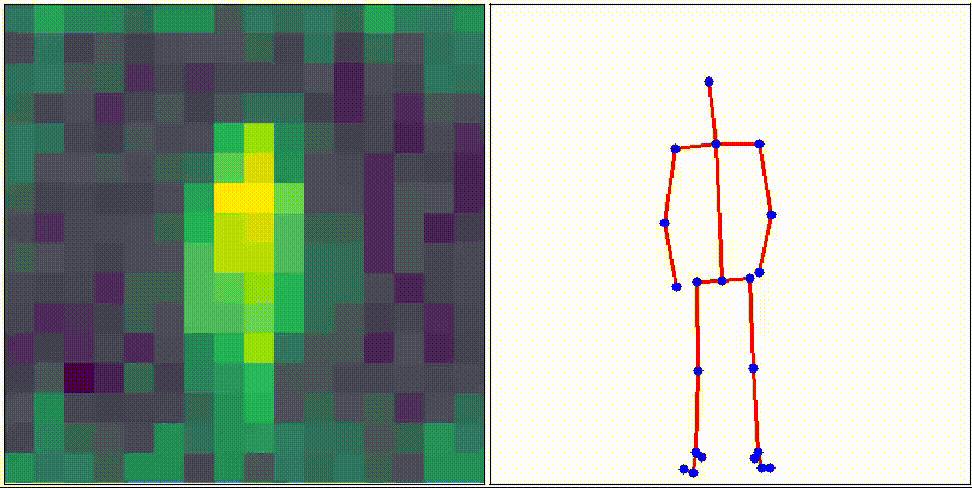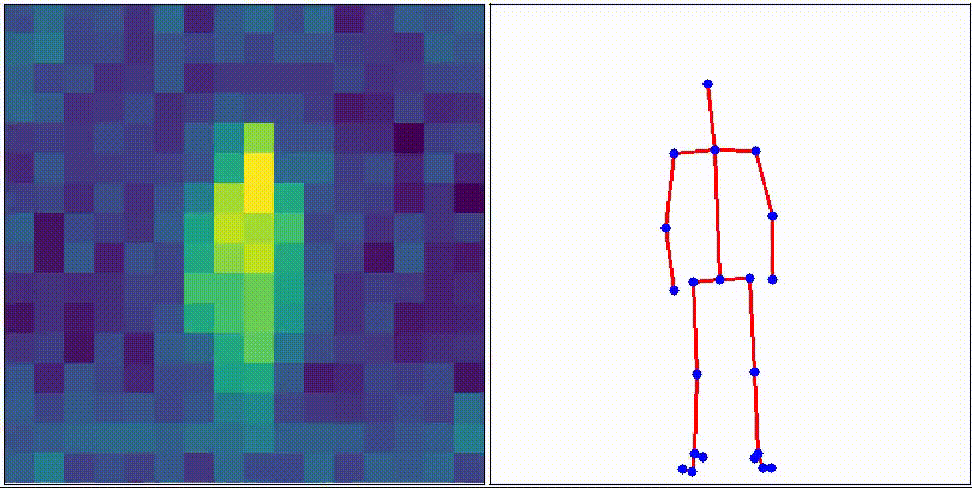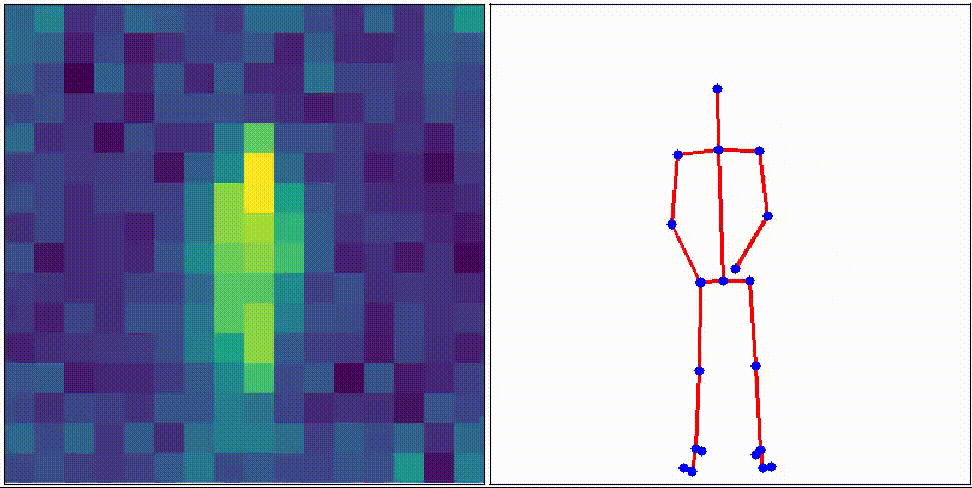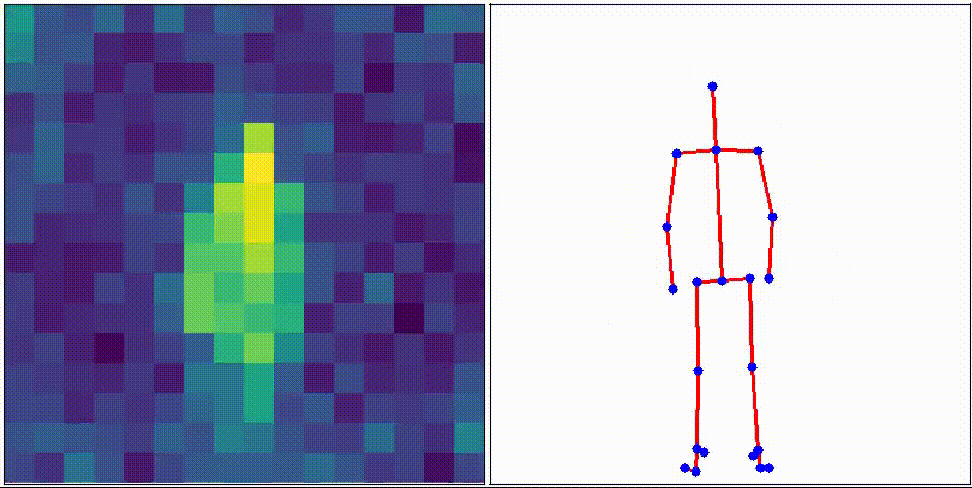

Object Pose Estimation
In recent years, robots have been developed for industries and daily life, and the task of carrying objects using robots is becoming more important.
In order to make this task possible, we are researching not only the recognition of objects but also the estimation of the object pose using an image sensor.
Person Recognition focusing on Behavior
In order to reduce the number of accidents in which visually impaired people fall off from station platforms, we are conducting researches to recognize whether they are visually impaired or not from the surveillance camera image, using the white cane, movement and pose of the user.
When searching for a specific person from surveillance camera video, it takes a lot of time and effort to do so manually
Therefore, we also conduct researches to automatically find the target person from long and numerous surveillance camera videos.




Environment Sensing Group
We research on environmental understanding such as vehicle ego-localization, obstacle detection, and map construction by using cameras and sensors mounted on automobiles. We also apply them to advanced driving support systems and automatic driving systems that make use of these elemental technologies.
Semantic Segmentation
In automated driving systems, it is necessary to accurately recognize the surrounding environment. For this purpose, “semantic segmentation” is used, which allocates a label of attribute such as “cars” and “pedestrians” to each pixel in an image taken with cameras on board vehicles.
In our Lab, we are applying this to researches that further divide the attributes of “pedestrians”, researches that automatically acquires runways, and researches that performs semantic segmentation to facilities along the railway.


Vehicle Ego-localization
In order to avoid collisions with surrounding objects in autonomous driving systems, it is necessary to accurately estimate the vehicle position and measure the relative distance from the object to be avoided. However, with GPS, position measurement errors due to radio wave conditions exist, so it is insufficient for use in automatic driving systems.
Therefore, we are studying methods that search for an image from a database with location information such as Google Street View that matches the image taken by in-vehicle cameras , and accurately estimate the vehicle position from the location information of the matched image.
Detectability estimation
For safer driving, driving assistance systems that assist safe driving by informing drivers about pedestrians and signs recognized by cars are being put into practical use. However, informing all pedestrians and signs to the driver is inefficient and may be discomfortable.
Therefore, we are researching a method to convey only difficult-to-see objects to the driver by estimating the visibility of pedestrians and signs from the driver's viewpoint.


Quantifying the relationship between language and images
When dealing with multimedia information, it is necessary to be able to use languages and images without barriers. Therefore, we are working on the field of “Vision & Language” which is now attracting attention.
For example, we focus on “imageability”, an index that shows how easy it is to image the content of a word when it is seen and heard, and we are researching how to quantify images by Web image mining. In addition, it can be used to analyze multimedia content such as articles, advertisements, and social media, and can be expected to generate attractive content.
We research on various themes using video and images.
Please feel free to contact us if you are interested.
Sitemap
Related links
Contact Information
IB Building South #457
Phone: 052-789-3310
Fax: 052-789-3807